
Изображение: https://ib-bank.ru/bisjournal/post/2015
В 2022 году группа компаний ЦРТ победила в международном конкурсе GRAM VAANI ASR Challenge, который был посвящён распознаванию спонтанной — естественной — речи в телефонном канале на языке хинди. Теперь распознавание речи от группы ЦРТ доступно на 14 языках: русском, английском, казахском, испанском, арабском, немецком, французском, турецком, бенгальском, филиппинском, фарси, урду, португальском, хинди.
В свежем выпуске BIS Journal — авторский материал об участии в конкурсе.
Участие в международном конкурсе по распознаванию речи на языке хинди — новый уровень для российских разработчиков: язык экзотичный, сложный, непривычный, а среди конкурентов были и команды, для которых этот язык родной. Именно поэтому победа во всех треках этого конкурса была особо значимой — она демонстрирует не просто распознавание ещё одного языка, а широкий спектр возможностей российских разработчиков в области распознавания речи. Качество распознавания речи и многообразие языков и диалектов укрепляют позиции ЦРТ в области речевых технологий, позволяют переводить сервисы из разряда инновационных в повседневные, позволяют совершенствовать речевую аналитику — автоматизировать работу контактных центров: распознавать естественную речь, делать выводы об удовлетворённости клиента и качестве диалога — существенно оптимизировать работу современных контакт-центров ретейла, e-commerce, телеком, а также создавать диалоговых ассистентов — интеллектуальных текстовых и голосовых роботов для крупного бизнеса и государственного сектора, с которыми легко и приятно взаимодействовать.
ОБ ОРГАНИЗАТОРАХ КОНКУРСА
Цель конкурса GRAM VAANI ASR Challenge 2022 — распознавание спонтанной речи на языке хинди в телефонном канале.
Gram Vaani управляет несколькими платформами голосовых средств массовой информации в Индии. Эти платформы работают на основе IVR: люди звонят по уникальному номеру телефона, объявленному Gram Vaani, после чего сервер IVR прерывает звонок и автоматически перезванивает человеку, делая звонок бесплатным для пользователя. Во время этого звонка пользователи могут записать голосовое сообщение, которым они хотят поделиться, или прослушать голосовые сообщения, оставленные другими пользователями. Эти голосовые сообщения охватывают различные области: новости, вопросы о сельском хозяйстве или здравоохранении, а также народные песни и стихи. После получения голосового сообщения модераторы Gram Vaani рассматривают его, и, если сообщение признаётся приемлемым, оно публикуется на платформе и может быть услышано другими пользователями. Пользователи могут добавлять комментарии, ответы или создавать собственные сообщения. Эти записи голосов тысяч пользователей Gram Vaani, соответствующие транскрипции, составили набор данных, на основе которого решалась задача конкурса.
О ПРОИСХОЖДЕНИИ ДАННЫХ
Набор данных включал в себя данные телефонного качества речи на хинди. Записи были собраны с помощью платформы Mobile Vaani, работающей с пользователями со всей Индии, и, следовательно, включают региональные и диалектные вариации хинди. Записи сопровождаются эталонными расшифровками — транскрипциями, сделанными сотрудниками, которые были набраны через крауд-платформу Uliza.
В конкурсе было представлено четыре набора данных.
- Отекстованные данные для обучения — 100 часов телефонных переговоров. По заявлению организаторов, эталонные расшифровки записей могли быть не очень точными.
- Неотекстованные данные для обучения — 1000 часов записей преимущественно из телефонного канала. Для этих данных расшифровки и детальные характеристики не были предоставлены.
- Отекстованный отладочный набор данных (devset) — 5 часов телефонных переговоров, для которых организаторы предоставили точные эталонные расшифровки.
- Отекстованный тестовый набор данных (evalset) — 5 часов телефонных переговоров, на которых организаторы проводили финальное сравнение систем распознавания. Эталонных расшифровок для этого набора организаторы не предоставили, чтобы исключить возможность подстройки систем под конкретный тестовый набор.
Данные были предоставлены в виде mp3-файлов, среди которых присутствовали записи с разнообразной частотой дискретизации (8, 16, 32, 44 и 48 кГц). Статистика по данным на рис. 1 и по ссылке.

Рисунок 1. Данные были предоставлены в виде mp3-файлов, среди которых присутствовали записи с разнообразной частотой дискретизации (8, 16, 32, 44 и 48 кГц)
ТРИ ТРЕКА
В конкурсе было заявлено три трека:
- Closed Challenge — для подготовки любых моделей можно было использовать только 100 часов отекстованных данных для обучения и 5 часов данных отладочного набора. Использование различных предобученных моделей в этом треке было запрещено. Необходимо было подготавливать систему распознавания с нуля, имея лишь данные обучающего и отладочного наборов.
- Self Supervised Closed Challenge — для подготовки любых моделей, дополнительно к изложенному выше, можно было использовать 1000 неотекстованных данных, предоставленных организаторами.
- Open Challenge — для подготовки моделей можно было использовать любые доступные данные (в том числе наборы с открытой лицензией, наборы, собранные самостоятельно из открытых источников, и т. д.), а также предобученные нейросетевые модели (экстракторы эмбеддингов, готовые системы распознавания, и т. д.)
Команда ASR группы компаний ЦРТ участвовала во всех трёх треках.
КЛЮЧЕВЫЕ УЧАСТНИКИ
В конкурсе участвовали ведущие мировые и индийские исследовательские команды, в том числе:
- LEAP LAB IISC & SRI — cовместная команда Индийского института наук LEAP LAB IISc и Американского некоммерческого научно-исследовательского института SRI (бывший Stanford Research Institute);
- Speech@SRI-B — команда исследовательского институтаSamsung R&D в Индии;
- CDAC_M — Индийский центр разработки перспективных вычислительных технологий CDAC_M;
- TU Delft — команда Делфтского технического университета в Делфте, Нидерланды TU Delft (старейший и крупнейший технический университет в Нидерландах);
- крупные индийские R&D-компании: Uniphore Software Systems — компания, специализирующаяся на ИИ в сфере речевого взаимодействия, в частности в кол-центрах, Cogknit и другие.
Полный список участников можно найти по ссылке. География участников на рис. 2.
Рисунок 2. География участников
НАУЧНЫЕ ПОДХОДЫ
В ходе конкурса нашей команде удалось применить разнообразные технологии, в том числе:
- Unsupervised и Semi-supervised-обучение экстракторов признаков. В рамках первого и второго конкурсных треков команда обучала с нуля модели, архитектурно аналогичные wav2vec 2.0. Такие модели для обучения требуют значительных объёмов данных, поэтому в первом треке мы использовали множество разнообразных техник аугментации обучающего набора данных. В том числе были использованы: аугментация кодеками (звук перекодируется различными кодеками со сжатием, а затем восстанавливается в формат, пригодный для использования в подготовке моделей), аугментация изменением скорости и громкости (speed and volume perturbation), аугментация в процессе обучения, заключающаяся в деформации спектрального представления звука — применение временнЫх и частотных искажений для маскирования блоков последовательных временных шагов или мел-частотных каналов. Во втором треке обучение таких моделей проводилось с добавлением неотекстованного набора данных в 1000 часов, с последующей адаптацией на 100-часовом отекстованном обучающем множестве. В рамках работ по третьему треку конкурса команда использовала предобученную модель wav2vec 2.0 (CLSRIL-23) в качестве экстрактора высокоуровневых признаков для дальнейшего обучения акустических моделей. Базовая CLSRIL-23 модель была дообучена в различных режимах на данных конкурса. Адаптированные модели позволили подготовить итоговые системы распознавания, которые на вход получают высокоуровневые эмбеддинги, и демонстрируют высокую точность распознавания.
- End-to-end модели. В ходе конкурса мы, наряду с классическим гибридным подходом, применили современный подход к построению систем распознавания речи, основанный на E2E-моделях. Был обучен ряд моделей на архитектуре Conformer. Как правило, такие модели весьма требовательны к объёму обучающих данных. Однако нам удалось подготовить E2E-модель с высоким уровнем точности распознавания даже для первого трека, в котором доступны лишь 100 часов обучающих данных. Во втором и третьем треках мы смогли в полной мере воспользоваться 1000-часовым набором для обучения E2E-моделей. На первом этапе мы подготовили текстовки для всех 1000 часов с помощью распознавания имеющимися у нас на тот момент классическими гибридными моделями. Для повышения точности подготавливаемых текстовок в распознавании мы использовали комбинацию таких моделей с последовательным применением нескольких постобработок (рескорингов результатов распознавания). Такая стратегия позволила нам получить максимально точные текстовки, которые мы затем использовали в качестве эталонных расшифровок при обучении E2E Conformer моделей для второго и третьего треков. В каждом из треков конкурса результаты распознавания E2E-моделями были использованы в комбинации с классическими гибридными моделями для получения финальных результатов распознавания.
- Различные виды постобработки (рескоринга) для улучшения итогового результата распознавания. Для получения итоговых результатов распознавания мы использовали несколько моделей для постобработки (рескоринга) результатов. Для первоначальной постобработки результатов мы применили нейросетевую языковую модель AWD-LSTM, которая перевзвешивала языковые веса в результатах распознавания, представленных в виде сеток. Затем, модифицированные сетки подавались на две более продвинутые нейросетевые языковые модели — GPT2-Hindi и Transformer. При помощи этих моделей гипотезы в сетках распознавания вновь перевзвешивались. В итоге результатом применения всего пайплайна постобработки являлись два комплекта сеток распознавания, каждый из которых был получен с применением разной последовательности моделей (AWD-LSTM → GPT2-Hindi и AWD-LSTM → Transformer). Стоит отметить, что ввиду ограничений в правилах конкурса для первого и второго трека использовалась только AWD-LSTM модель, так как доступный объём текстовых данных позволял обучить только подобного рода архитектуру.
- Для получения итоговых результатов распознавания в каждом из треков использовалась комбинация наилучших соответствующих комплектов сеток (результатов распознавания от различных систем с применением подходящих стратегий постобработки). Параметры комбинации моделей определялись на отекстованном отладочном множестве данных и затем применялись в ходе формирования финальных сабмитов с результатами для тестового множества.
РЕЗУЛЬТАТЫ КОНКУРСА
Наша команда (STC) заняла первые места во всех трёх треках (рис. 3).
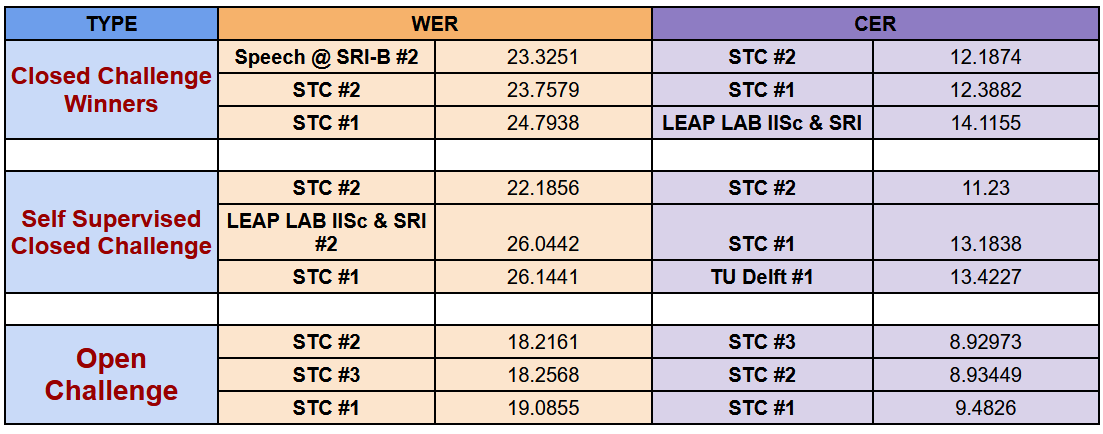
Рисунок 3. Результаты конкурса. Наша команда (STC) заняла первые места во всех трёх треках
Полная версия результатов всех участников доступна по ссылке.
Комментарии:
- В closedchallenge мы немного уступили по WER (на 0,4%), однако значительно оторвались по CER (на 1,9%) от ближайших соперников. Стоит отметить, что результат команды Samsung (Speech@SRI-B #2), показавший лучшее значение WER, по CER уступил нашему на более чем 2%.
- В треках self-supervised и open challenge мы продемонстрировали результаты, значительно превосходящие результаты соперников как по WER, так и по CER.
- Рядом с названиями команд #1 #2 #3 обозначают номера сабмитов (каждая команда могла отправить три результата распознавания по каждому из треков).
Для оценки качества распознавания речи традиционно используются метрики пословная ошибка распознавания (worderrorrate, WER) и посимвольная ошибка распознавания (charactererrorrate, СER). Чем меньше значение этих метрик, тем лучше качество распознавания речи.
Для получения оценки WER сравнивают последовательность распознанных слов (результата распознавания) с последовательностью сказанных слов (эталонной текстовкой). Производится сопоставление (выравнивание) этих двух последовательностей, которое обеспечивает минимальное количество вставок, удалений и замен слов, позволяющих преобразовать идеальную текстовку в результат распознавания. Такое количество называют «редакционным расстоянием» (расстоянием Левенштейна) между двумя последовательностями слов. WER измеряется в процентах:

, где
I – вставки (Insertions), количество добавленных в исходную строку слов,
D – удаления (Deletions), количество удалённых из исходной строки слов,
S – замены (Substitutions), количество заменённых слов,
N – количество слов в исходной строке.
Метрика CER рассчитывается таким же образом, но учитывается количество добавленных, удалённых и заменённых символов без учёта пробелов.
Для хинди обе эти метрики крайне важны, так как язык является символьным, текст на нём выглядит примерно так: नादयाऔररामकीबिल्ली.
Источник: https://ib-bank.ru/bisjournal/post/2015